Rough outline of the issue
On 27.02.2024 at about 09:35 UTC we noticed a huge amount of problem reports about packet loss in our network. After a quick investigation we noticed that the rpd (routing process) on one of our redundant gateway routers started using too much RAM. Reboots of the redundant gateways solved the issue only for a couple of hours and even after further debugging we could not find any issues on our side causing this.
Here is a picture from our monitoring system showing the rapid rise of used RAM:
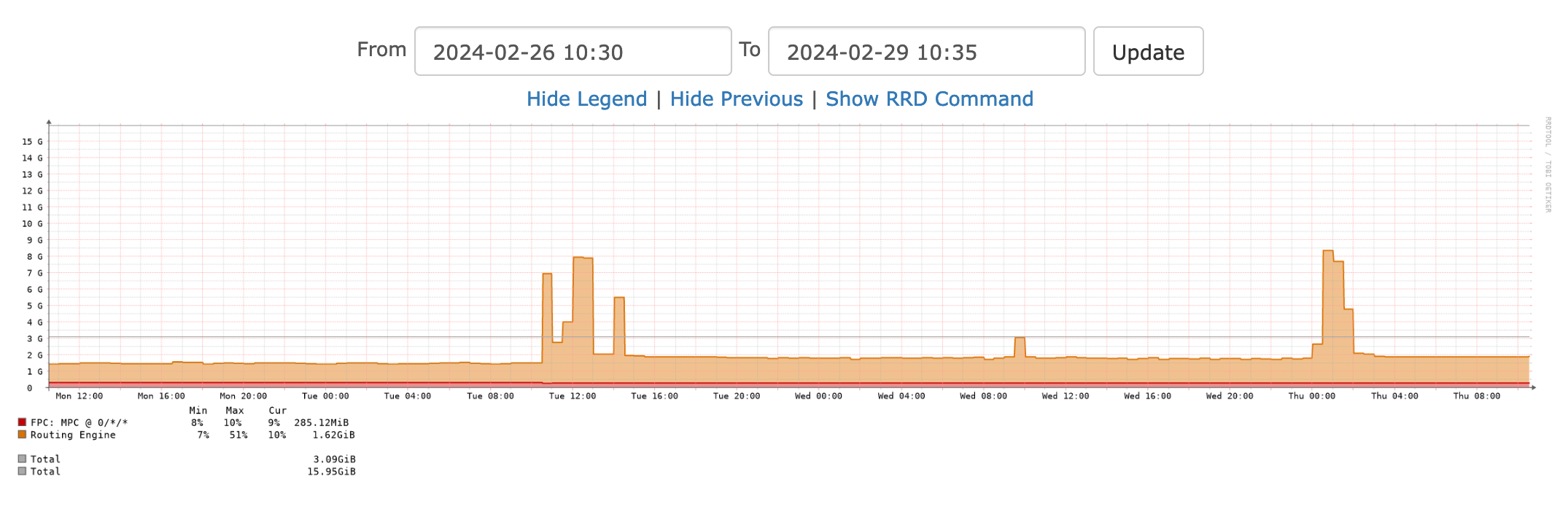
As we could not solve the situation on our own and suspected a software bug (memory leak) we contacted the Juniper support. After first investigation with Juniper we deactivated the second gateway and the situation normalized. The network was stable again but we were missing a critical element in our backbone.
During the next days and nights we had to gather debug information from the device in the faulty state. For this we had to bring the device back into the problematic state and had to collect several log files and debug information.
After several debug sessions, Juniper finally found a bug which was connected to our problem (Link to the PR which was just released today). In an EVPN-MPLS setup when there is a MAC address having more than 300 IPs bound to it can cause high CPU and RAM load on the system. In our case this lead to packet loss.
In order to solve the problem we requested an action plan from Juniper. We had to
- contact the customers using more than 300 IPs bound to a single MAC address
- have them reduce the number of bound IP addresses
- gather further debug information on FPC level
We carried out the action plan immediately and could re-integrate the problematic gateway router into our network on 11.03.2024.
Implementation of the final fix
We received the information from Juniper on 15.03.2024 that the issue has been fixed and we received a list of versions containing the fix. We scheduled a maintenance window for 18.03.2024 at 23:00 UTC.
Unfortunately, we had to prepone the maintenance as the CPU load started to rise over the weekend. The final fix was implemented on 18.03.2024 between 10:00 and 12:00 UTC.
Here you see a graph from our monitoring system showing the CPU load rise:
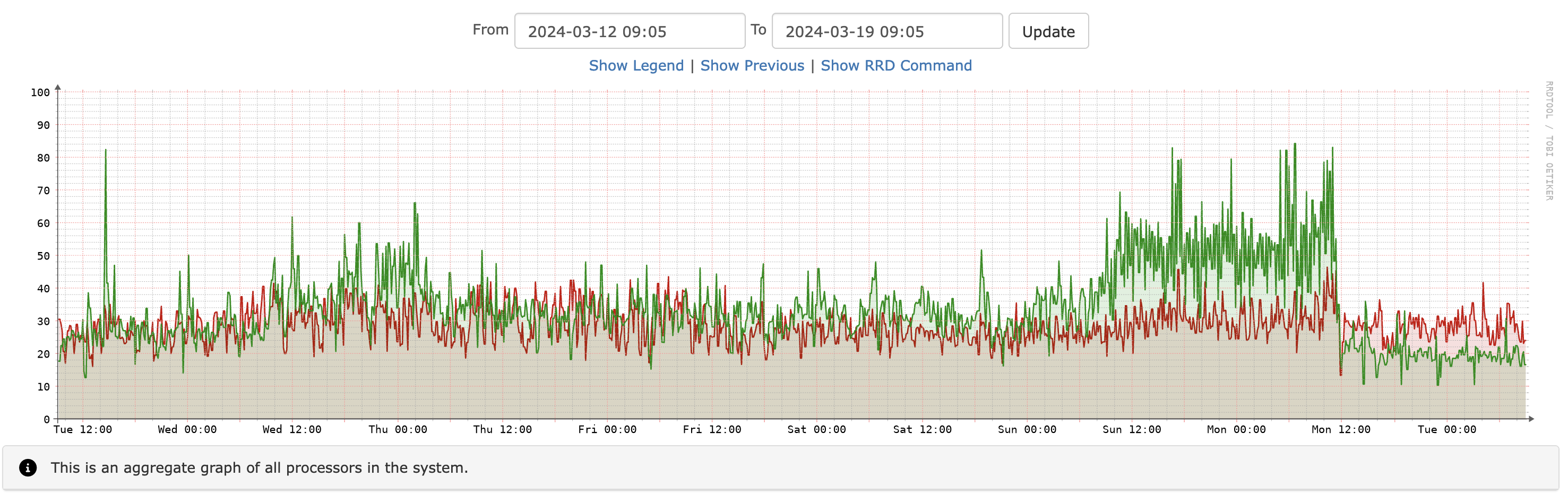
Lessons Learned
Even if the PR was classified as minor you can see that a minor bug can have huge impact on a network. In our case we were hit by a software bug which we could not solve on our own - our hands were bound.
During this incident we have noticed one point: We will further optimize our communication with our customers as this still has some potential for improvement.
We are still in touch with Juniper to put together all their findings. We will send out a postmortem with further details this week.
In the meantime, we have made some adjustments with some customers which we were told to do. We plan to reintegrate the other gateway in the coming week.
In EVPN-MPLS networks where many IPs are bound to a single MAC under certain circumstances the rpd may get stuck. This only happens when all-active multihoming is used and two or more PE-Devices are active. The problem is related to the l2ald process.
We now have an action plan and will contact certain customers who may have been identified as causers of this problem. A longterm fix will be provided by Juniper later as engineering is now also involved.
In the actual state the network is stable and we do not have to expect any issues.
Until the situation is solved we will not be able to activate any new customer services relying on network changes to our platform.
The situation is stable.
Despite our best efforts it will not be possible to avoid short periods of further packet loss from occurring. Please excuse any inconvenience.
Until then traffic will stay re-routed and the network is stable.
If the problem persists, packet loss could occur again.
Traffic is currently re-routed and you should see no disruption anymore.
We will be re-routing traffic until the cause can be fixed.